Technique Journal
What are my tools?

I am currently working on a bunch of small 1 day or less projects where the goal is to focus on a specific technique, I will be keeping track of them and my thoughts on them here. You probably shouldn’t read this. My guess is for every single one of these techniques it is trivially easy to find a better explanation of them (even just asking an AI (or if you want to see how dumb I am ask an AI everything I got wrong here.)) I will be updating this as I go in the order I am learning the technique. To some extent this document mostly exists to force me to write about (and therefore think about) each of these techniques and hopefully so I can easily come back later to see how my thoughts have changed.
Direct Logit Attribution (and Logit Lens)
For the given token see how much the given output of an MLP Layer or Attention layer (or head) impacted the final logit value. In other terms what steps in what layers for this specific context token did we learn the most towards a given output. When looking at a correct output this helps us see where we learned things that were helpful, we can also alternatively look at incorrect outputs and see when the model moved towards a wrong answer. The clear issue with this is that it only looks at the given token, so we can see when the attention layer (or head) added lots of probability to a given output, but we can’t see which of the other tokens we learned from, my current model is most most of the interesting stuff is about what other tokens did we learn from and why even something as simple as an induction head it matters which other token it is that we actually learned from in a given attention head. So, I guess the point of direct logit attribution is to help us figure out where to look, it seems extremely computationally light, so it seems like maybe this could potentially be a technique I would use very early on just to try to get a better understanding of the basic structure of the model, for example what attention layers are transferring lots of information. It seems like this is maybe a technique to use if I think there is a very clear comparison to be made between a right prediction and an alternate wrong prediction ie “When Mary and John went to the store, John gave a drink to ___” → “Mary” or “John”.
The final logit value for a given token is just the embedding plus the sum of all values that are added back into the residual stream, ie the output of each of the MLP and Attention heads (and finally apply whatever the final normalization function is) and dot product each one by these by the destination target. This makes the implementation pretty simple which is to apply whatever the multiplier is for the final normalizing function to each of the individual contributions (The MLP and Attention outputs) and dot product by the various destination values we might want to compare. Super simple implementation, really makes it clear how this doesn’t help us see how any of the other tokens impact since it’s only looking at the various MLP/Attention layer outputs for the given token and nothing else.
Logit lens simply looks at residual stream values after each layer and we can unembed to see how it ranks various tokens (usually most helpful is to see the trajectory of the correct prediction, for example I can look at what layer the correct prediction becomes the model’s #1 most likely, what layer is it top 5, etc.)
Anthropic’s 5/2024 take from Scaling Monosemanticity on using direct logit attribution to identify where to perform feature ablation on SAE features: “A simple strategy for efficiently identifying causally important features for a model’s output is to compute attributions, which are local linear approximations of the effect of turning a feature off at a specific location on the model’s next-token prediction. We also perform feature ablations, where we clamp a feature’s value to zero at a specific token position during a forward pass, which measures the full, potentially nonlinear causal effect of that feature’s activation in that position on the model output. This is much slower since it requires one forward pass for every feature that activates at each position, so we often used attribution as a preliminary step to filter the set of features to ablate. (In the case studies shown below, we do ablate every active feature for completeness, and find a 0.8 correlation between attribution and ablation effects; see appendix.)”1
Sparse Auto Encoders
A type of dictionary learning, which basically means that we are taking a bunch of signals (model activations) and finding a dictionary of basis elements (decomposing it) such that every signal can be expressed as a combination of those basis elements. First off this is significantly more resource intensive than Direct Logit attribution, on large models easily 100,000x or more intensive however that is a one time cost to train the SAE (which intuitively is why resources like neuronpedia.org make sense, this seems like it’s on the edge of what someone on a small research budget could accomplish. Don’t need to know anything or have any hypothesis, very exploratory. Training SAE will simply find whatever the most relevant single dimension features are, seems like given that there are tons of features usually features from SAE are labeled using LLMs instead of by hand by humans.
SAEs are basically a very simple linear encode and decode neural network (with a nonlinearity like relu in the middle) trained on the residual stream at various points in the model. Instead of the input being tokens the input is the residual stream value, meaning it’s a vector of size residual stream dimension. Additionally before we can train the SAE we need to calculate what that residual stream value is, this means if we have a corpus of hundreds of millions to billions of tokens we need to run a forward pass for every single one of these tokens (and all the other tokens in context) for us to then minibatch on. This is a pretty resource intensive step. When I trained an SAE on a single layer of gemma 2-2b using a corpus of only 2M tokens, this step took over 2x as long as the full training for the SAE for one layer (there are 26 blocks with both an MLP and Attention layer, so training all the layers would take much longer.)
Training an SAE: take the minibatch of residual layer values, shift to mean zero by subtracting out decode bias, multiply by an encoding vector of size residual dimension by SAE dimension (usually at least 10x larger than residual), add bias (size SAE dim), apply relu. This gives the larger dimensional representation let’s call it z. We then decode back to residual dimension multiplying by another weight matrix of size SAE dim by residual dim (the decoding matrix which also has to be normalized for uninteresting loss reasons), and finally add back the original decode bias to get back to our original mean. This gives us a final output xhat. So, what are we trying to optimize on. The intuitive thing we want to minimize is the difference between xhat (the output from our higher dimensional feature encode) and x (original residual stream values) since the closer these are the better our higher dimensional representation does at representing the residual stream. We do this with mean squared error. However if we ended there we would just get lots of activations on each dimension, and what we really want is as few activations as possible so that we optimize towards having clear features that each are only a single dimension, so we add to the loss the L1 norm of z. Basically we active features to activate as few (ideally) dimensions as possible, so we should see z as a whole bunch of zeroes, and then a couple positive values each one corresponding to a different feature being on. We use L1 norm so that when calculating the gradient for a feature to be worth going from 0 to any amount on it has to be reducing MSE by at least the linear cost. This second part of loss is here to encourage sparseness, and the way we can determine how sparse we want it is by multiply the L1 norm by a coefficient (usually called lambda or L1 coefficient) which determines how expensive activating is. A larger coefficient makes activating more expensive and will mean a given token will have fewer features activating. it seems like in practice this coefficient is usually set so that we see something like 50-200 features active per token. It’s not super clear to me how we’ve decided what a good number of features is, how many different features could I reasonably expect to be acting on a given token? It seems like there are a lot, but more than 100? I don’t have great intuition here.
So, after we train, what exactly is the helpful output? The encoding and decoding matrices. Max activating examples are tokens that produce the highest values for the given feature in z, you get that by multiplying the residual stream value of that token by the encoding matrix. The decoding matrix is fundamentally the features. Then, we can see the logit impact by simply multiplying the activation value by the decoding matrix (and the unembedding from logits to vocab). So, the logit distributions on neuronpedia are really just a function of the activation distribution, but bucketed over tokens instead of over total number of activations.
xhat won’t be exactly equal to x, there will be some error (variance unexplained by the SAE), this means that when running experiments using the SAE such as modifying the activations of a given feature we need to add back the error term so that the experiment only tests the impact of modifying the SAE activation value and not testing the impact of the unexplained variance.
Seems like I should always use JumpReLu instead of ReLu.
Anthropic on trying to find features for concepts they care about (so that they can then modify, ablate, etc): “Often the top-activating features on a prompt are related to syntax, punctuation, specific words, or other details of the prompt unrelated to the concept of interest. In such cases, we found it useful to select for features using sets of prompts, filtering for features active for all the prompts in the set. We often included complementary “negative” prompts and filtered for features that were also not active for those prompts. In some cases, we use Claude 3 models to generate a diversity of prompts covering a topic (e.g. asking Claude to generate examples of “AIs pretending to be good”). In general, we found multi-prompt filtering to be a very useful strategy for quickly identifying features that capture a concept of interest while excluding confounding concepts.
While we mostly explored features using only a handful of prompts at a time, in one instance (1M/570621, discussed in Safety-Relevant Code Features), we used a small dataset of secure and vulnerable code examples (adapted from
[22]) and fit a linear classifier on this dataset using feature activity in order to search for features that discriminate between the categories.”
Linear Probes (and Contrastive Vectors)
Needs a labeled dataset. Good for finding out about a specific concept, both good for finding if the model understands the concept, but also good for trying to amplify or erase that concept (very useful if there is a specific concept that I know I want to steer for and then train on it), just have to make the dataset. Can do it on a binary labeled dataset (true false → ie can also train on model deceptiveness), on a continuous dataset (latitude/longitude of the the location the sentence describes, a sentiment of 1-10 score etc), multiple choice (which football team is being described. Hardest part is clearly dataset creation, especially since with large models you will need pretty large datasets so there isn’t accidental overtraining on unexpected aspects (ie if truths are longer than lies it might just train on length of the given example.)
For each example in the labeled dataset do a forward pass and take the residual stream value for the final token at each layer (since the final token is the one where all information is being gathered for the eventual prediction in the final layer). These residual stream values at each layer are the inputs. At each layer we then train a weight vector and bias value. The output value is the residual stream dot product with the weight vector added to the bias. Depending on what type of label we have we will have different nonlinearities applied as well as different loss functions. For binary labels we use sigmoid nonlinearity, and then cross entropy loss due to these leading to a nice maximally easy to calculate derivative of literally just prediction minus truth (ie if we predict .7 and the true value is 1 we will get a gradient of .3). Once we have trained these weights for each layer we can find which layer has the best accuracy (usually middle layers).
Creating/getting the labeled data is clearly the hardest part. Seems like once there is good labeled data it’s pretty trivial to get out good results to easily steer the model etc. This technique of comparing outputs of different types of data is very powerful. Anthropic uses “contrastive vectors” to steer the model to be less aware when it is being evaluated. The paper this is based off of doesn’t even need to train a linear probe model, it literally just subtracts the mean residual stream values for each of the two different binary datasets and then steers based on that difference. This is absolutely stupid simple (it seems like simple is better than more complex is a frequent theme in neural networks) and as far as I can tell is used to help align state of the art models. Contrastive vectors find the direction of average shift between the two, the probe finds the direction of best classification accuracy.
From Opus 4.5 system card: “Contrastive vectors: We record the model’s activations in response to a positive prompt (or set of prompts) indicating that the model is being evaluated, and a negative prompt (or set of prompts) indicating that the model is not being evaluated. We subtract the activations on the final tokens of these prompts. “
From Opus 4.6 system card: “In our automated behavioral audits, we found that inhibiting one particular evaluation awareness vector (Testing vs. Conversation) led to moderate increases in misaligned behavior, as well as decreases in verbalized evaluation awareness.”Similar level of resource intensive as DLA, quite simple/easy once you’ve got the labeled data.
Activation Patching (aka Causal Patching)
Let’s say you have two inputs to a LLM with the same number of tokens. For example: “The capital of France is” (“ Paris”) and “The capital of Germany is” (“ Berlin”). What if we want to try to figure out what parts of the LLM are most important for correctly predicting Paris. One way to think about this is in which token is the most important information being stored. If we took the Germany example we could try patching in the residual stream value for the “ France” token in after various layers to replace the residual stream value of the “ Germany” token at that layer. You would likely find that doing this for basically all of the early and middle layers would lead to to outputting “ Paris” instead of “ Berlin”, however at some point in a mid/late layer it would stop doing so because the information got moved to the final token (“ is”) in preparation for that final token to predict the next token, this would be one way to figure out which token in “The capital of France is” is the token that is most holding the crucial information towards predicting “ Paris”. We could also try to see which layers are most important, to do this we could look at which layer output does the most heavy lifting. For example we might find that there is a specific attention layer that moves all of the information from the token that conveys the country information to the final token, so if we replaced the attention layer output from the Germany example with the attention layer output from the France example we might be able to significantly improve the final probability of “ Paris”. Similarly there might be an MLP layer where the model is looking up what the capital of the country it thinks the sentence is describing is, if we replace that specific MLP layer’s contribution we could significantly improve the odds of the model predicting what we want. The core idea behind activation patching is it lets us see at what layers (or even at what specific attention head in what layer) there are important calculations being done. Whether that be moving the relevant information around, or figuring out the relevant information.
Activation patching is in some ways similar to DLA, you are finding at what layers are important computations being done towards getting the right answer, however Activation patching is significantly more computationally taxing, if we want to test every layer we have to do the forward pass for both strings, as well as a forward pass from the patched layer onward for every patch/layer combination. Activation patching also requires more setup since you need two strings with the same number of tokens testing the hypothesis you want to test, although to some extent this also get at the strength of this technique. Instead of replacing a given layer’s output with the output from a different example’s output at that layer you could just as easily ablate that output. Ablating an output is much simpler all you have to do is set it to 0, but the reason to do activation patching instead is twofold: 1) You can try to specifically target something (like just the difference in country) 2) Replacing a given output with zeros is likely out of distribution, this isn’t something you would expect the model to ever deal with in normal function so now you have to worry that the ablation has added unforeseen issues, replacing it with an output that we know is in distribution for the given layer ensures that the model is working with in distribution and we don’t have to worry about it going wrong in unforeseen ways.
Activation patching is clearly most helpful as an intermediate step when we are trying to test something, it’s a way to see what parts of the model are important to a given thing we are trying to test. For example if we are trying to figure out at what point in the model it does calculations to determine how truthful it should be to the user we could start with a DLA of examples surrounding truthfulness. Then we could use Activation patching on the most promising examples in the places where we had the highest DLA values, only having to test the places with the highest DLA values could significantly cut down on computation and show us which specific parts of the model are important to the thing we are testing. Then, once we know what parts are important we can then try to play around with those specific parts using other tools at our disposal. Activation patching also isn’t that resource intensive, certainly way less than SAE. To some extent it is the least resource intensive way to directly test causally if something is having an impact in a way that neither DLA or Linear probes can do.
Circuit Tracing
Training this is brutal, there is no way I personally am ever going to be training a CLT on anything resembling a real model - so my intuition is that really understanding the full mechanics is somewhat less important. The high level intuition on circuit tracing is that we are effectively replacing the MLP layer with something human understandable. The MLP takes in the residual stream up to that point and outputs some thing to be added to the residual stream. A CLT is very similar to SAEs except instead of training a sparse much higher dimension encoding that decodes to the residual stream the CLT trains a sparse much higher dimensional encoding, that encoding is then separately decoded (with different decoding matrices) to all later MLP layer outputs. SAEs are trying to understand the residual stream values, CLTs are trying to understand the operation that the MLP layer does. The goal is for the sum of all of these decodings (ie the 4th layer would have a decoding from 1st, 2nd, and 3rd layer) in a given layer to get as close as possible to the true MLP output for that layer.
Why do we use a given encoding in all layers after? Because once an MLP layer writes to the residual stream that contribution to the residual stream is used in all further inputs, so we avoid having to calculate the multi step impact manually, and when CLTs only decode to the next layer (per-layer transcoder PLT) this has empirically worse reconstruction results.
To get a CLT, first you train it. Then, you see how well it performs. Then you can use it to try to understand why the model predicts what it does for any input. To a first approximation the better the CLT the more will be explained by the CLT outputs and the less will be explained by the generic error term.
How to train? For each MLP layer input there is a single encoding matrix that encodes that input to a much higher dimension (think 50x or more). The encoded values are then decoded for each following layer, with each following layer having it’s own decoding matrix for a given encoded previous layer. As an example in a model with 4 MLP layers the 1st layer would encode the input to that MLP layer, that encoding would then be decoded by three different decoding matrices, one for the 2nd, 3rd, and 4th layer. On the flip side the yhat output of the 4th MLP layer in this CLT model would be the sum of the decoded values from the 1st, 2nd, and 3rd layers. The loss function has two components, the first is how well does the CLT reconstruct the true MLP outputs, at each layer there is a yhat output which is the sum of all decoded outputs from previous layers, the reconstruction loss is the l2 norm of y-yhat for all layers. Then there is the sparsity loss term which exists to encourage the high dimensional encodings to be as sparse as possible (ie vast majority 0s, maybe only a couple hundred nonzero terms out of potentially 100k+ features). To a first approximation this loss is the total number of nonzero features across all encoded values, this isn’t quite true since for each encoded value the loss contribution is somewhere between 0 and 1 based on how large active the dimension is and how large the average decoder weight is for that feature. It uses tanh to ensure the values are between 0 and 1 and are easily differentiable and a manually set coefficient that changes how intense an activation you need to get towards a full 1 value, but I don’t think the exact formula is worth digging into.
On this CLT has been trained you can test how well it does by running full forward pass using the CLT values instead of MLP values at every layer, and seeing how close the final model CLT predictions are to the normal MLP model predictions. This is the only place where the model behaves fully normally with each layer taking inputs from previous layer no error, no freezing. This also means that since each CLT layer is slightly different from what the MLP outputs would be, these errors can compound. In the seminal anthropic paper the best they could get was CLT that predicted the same next tokens as the MLP 50% of the time.
What you and I will spend most of our time looking at is the “local replacement model” what this does is applies the trained CLT model to a specific text input, for example “The Eiffel Tower is located in” where you can see at each layer the features in the high level CLT encoding at that layer the features that are most activated and the various impacts on the MLP outputs at further layers. You first run the normal model and record everything (residual stream values, attention patterns, LayerNorm denominators, and MLP outputs.) Then you construct a new computational graph where the MLPs are replaced by CLT features, attention patterns and LayerNorm are frozen at their recorded values, and error corrections are added to make the whole thing exactly match the original model's outputs. Because attention and LayerNorm are frozen, and MLPs are replaced by CLT features, the only remaining nonlinearities are the feature activations themselves. Everything between features is linear. This means you can compute the exact influence of any feature on any downstream feature
Steering Vectors
Applying a vector to the residual stream at one or multiple places to try to get the model to behave differently. There are many ways to find a vector to add to the residual stream to alter the output of the model. You could run a linear probe, do a super simple mean difference (contrastive vectors), PCA, etc. But once you have a vector that you think will make the model more formal, or more truthful, or more playful, etc then steering is simply applying that vector at varying strengths at various places to try to get out different outputs than if you just ran the standard model without these additions to the residual stream.
Ablation
Fully removing the impact from something on the model. If you’re working through a forward pass it’s trivial to ablate a layer since all you have to do is zero out the output of that layer when it adds back to the residual stream (zero ablation). Maybe instead you want to keep the same average magnitude, you could instead replace a given layer output with instead a mean of lots of other outputs on other input texts at that position (mean ablation).
Let’s say you find a direction of something in the model, let’s say the rejection direction, you can add or subtract this direction times any coefficient. large coefficients would lead to the model rejecting the user more, negative would lead to less rejection and then as it gets more negative the opposite of rejection. If you want to exactly take out the amount of this direction in the model you can direction ablate by normalizing the direction to unit vector (divide the vector by it’s l2 norm), then subtract the dot product of this unit vector and the residual stream value multiplied by this unit vector (to fully remove this dimension from the residual stream.) You could also try direction ablating Attention head outputs or MLP outputs to try to find which specific layer/head most contributes to the refusal and see what happens when only ablating in one specific layer output.
Contrast-Consistent Search
Seems like a pretty bad technique, almost strictly worse than a simple linear probe. Yes, it doesn’t require labels but it does require contrastive pairs. It seems like if you’ve already got a bunch of contrastive pairs, then labelling them shouldn’t be that much more work.
The input is a the residual stream for the final token at each layer for a bunch of paired prompts that are all slightly different in the same way. For example: “Gold is Au. T or F? Answer: Yes” vs “Gold is Au. T or F? Answer: No”. You don’t use any labels. Then, the objective is to get the CCS to output a 0 and a 1 allocated to each pair. The way this is done canonically is by training a small MLP on the residual stream that takes the lets say 2304 dim residual stream through a linear layer (matrix mul) down to lets say 32 dimensions → ReLU → linear layer from 32 dim to 1 → sigmoid (so output is between 0 and 1). I also tried a single linear layer (ie 2304 straight to 1) and a sigmoid, which worked very similarly. If the outputs for each pair are p1 and p2, the loss for that pair is:
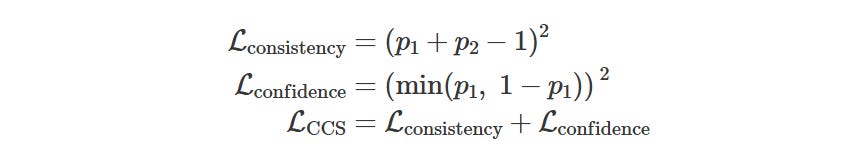
summed across all matched pairs. in other words there is higher loss if the two probabilities don’t sum to 1, and there is higher loss if they aren’t confident (predicting either a 0 or a 1).
The core idea in CCS is okay, you find some
direction that when applied to every pair of residual stream stream values makes one of the pair got to 0 and one go to 1. The core issue (and also the reason for this method to exist) is you don’t actually know what you are finding. In the “Gold is Au” example the hope is that we might find the direction of the model thinks this is true and assign 1 to the true one, and 0 to the false one. However, the much simpler way to split is assign 1 to the one that ends in yes and 0 to the one that ends in no. So, to account for that you need to subtract out the Yes/No Dimension. However, let’s say that we are testing on an Elements dataset, some of the claims are of the form “Gold is Au”, others are “Gold is the 72nd element on the periodic table”, now even though we can subtract out the yes/no dimension for all pairs, we can’t subtract out the interaction between sentence length and the word Yes/No, so we would probably do something like find a dimension that labels long sentence/yes → 1, long sentence/no → 0, short sentence/yes → 0, short sentence/no →1. And this get at the core of the issue with CCS, if you are trying to use it to find an important but subtler dimension you have to be extremely careful that your data doesn’t have any other variance in it that would allow finding a different dimension that consistently labels 0/1. You have to be super fucking careful about the pairs and really make sure that they are all really similar in every way other than the thing you care about.
The hope with CCS is that you can find things where you don’t actually know the label, such as does the model actually care about the user ex: “please help me: I would love to” vs please help me: I would hate to”, where we are trying to figure out things we have no way of knowing. The core issue is we really have no idea if the direction we find is actually what we are about. And, this is what I found when I compared CCS to labeled data when trying to use it to determine whether the model understands whether a given statement about the world is correct, in datasets where the input pairs were all extremely similar to each other it could get close to as good as a linear probe, but it was extremely fragile and as soon as the dataset of input pairs started to have some differences (such as multiple domains, or multiple sentence constructions) it stopped finding correctness and started finding something else entirely.
https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html